Understanding Reified Relationships, N-Tuples, and How They Give Life to Data
In data modeling, relationships are often treated as mere connectors between entities—invisible wires that link records together without carrying meaning of their own. Reification changes that. By promoting a relationship into a first-class data object, reification allows the connection itself to be stored, described, queried, and extended. The shape of that resulting object—the number and nature of its attributes—is what N-tuple notation captures. When enough reified relationships are assembled around a node in a graph, they collectively form what can be called a Knowledge Profile (KP): a rich, queryable, semantically expressive picture of everything the graph knows about that node. But building and maintaining complete Knowledge Profiles at scale quickly overwhelms manual human effort. This article explains what reification means, what a reified relationship is, how N-tuples describe the richness of the resulting records, what Knowledge Profiles are and why they matter, why manual approaches fail at scale, and how automated data compilers offer the only viable path forward.
NOTE: This is an IF4IT-authorized republication of the original article authored by Frank Guerino.
Overview
Every data system is built on two foundational concepts: nodes and relationships. Nodes are instances of specific data types—a particular Person, a specific Organization, a named Product, a recorded Transaction. They are the concrete, typed data objects that a system tracks: not the abstract concept of a person, but the instance "Jane Doe, Person, born 1984, residing in Boston." Relationships are the edges that connect those node instances to one another—the links in a graph that say: this specific node is connected to that specific node.
In many data systems, relationships are treated as second-class citizens. A bare 2-tuple relationship containing only the source node and the target node answers one question: are these two instances connected? It cannot say how they are connected, why they are connected, when the connection began, what role each node plays in it, or how the connection has changed over time.
Reification is the solution. It is the act of taking a relationship—something abstract and implicit—and turning it into a concrete data record in its own right. Adding a predicate to the 2-tuple—"Jane Doe is the Spouse of John Doe"—begins to describe the nature of the connection. Adding further tuple attributes deepens that description further.
As the reified relationships connected to a node accumulate and grow richer in tuple depth, they collectively form that node's Knowledge Profile (KP): the totality of what the graph knows about that node, expressed through its relationships. N-tuple notation provides the vocabulary for describing the structure of individual reified relationship records, and therefore the richness of the Knowledge Profiles they contribute to.
What Reification Means
The word reification comes from the Latin res, meaning thing. To reify something is to make it into a thing—to take something abstract, conceptual, or implicit and give it a concrete, tangible form.
In data modeling, reification has a precise technical meaning: it is the act of promoting a relationship between two or more nodes into a data object—a record—in its own right. Rather than existing only as an implicit link between two node instances, the relationship becomes a first-class data entity that can be stored, queried, updated, versioned, and extended with its own attributes.
Consider a simple example. In a basic data model, the fact that Employee A is assigned to Project X might be represented as a direct link between the employee node and the project node. That link carries no additional information. There is no assignment date, no role, no percentage of time allocated, no start and end dates, no approval status.
Reification replaces that implicit link with an explicit record—an Assignment entity that represents the connection itself. That Assignment record can now carry all the attributes the connection needs: who, what, when, in what role, for how long, and under what conditions. The relationship has been made into a thing.
Once a relationship is reified, it becomes a full participant in the data system. It can be created, updated, versioned, queried, and deleted independently. It can have its own lifecycle. It can contribute to the Knowledge Profiles of every node it connects.
What a Reified Relationship Is
A reified relationship is a data record that represents what was previously an implicit connection between nodes. It is the concrete output of the reification process: a first-class data object that captures the fact of a connection and carries the attributes needed to describe it.
Reified relationships appear across every domain of data modeling, often under different names. In relational databases, they are sometimes called associative entities, junction tables, or bridge tables. In knowledge representation, they are called reified triples or named graphs. In object-oriented modeling, they are sometimes called association classes. The terminology varies, but the underlying concept is consistent: a connection between node instances that has been made into a data object.
Consider a few examples across different domains:
Employment: A reified relationship between a Person node and an Organization node captures not just the fact of employment but also the start date, end date, job title, department, employment type, and compensation band.
Enrollment: A reified relationship between a Student node and a Course node captures the term of enrollment, the grade received, the section number, and the credit hours earned.
Prescription: A reified relationship between a Patient node and a Medication node captures the prescribing physician, the dosage, the frequency, the start date, the end date, and the indication.
In each case, reification allows the data system to capture not just that two nodes are connected, but how, when, why, and under what conditions that connection exists.
Data Integrations as Reified N-Tuple Relationships
The concept of a reified relationship has a direct and underappreciated parallel in a domain that every IT organization manages: data integration. In the IT industry, a fully described data integration is itself a form of a complex reified N-tuple relationship. It represents not just the existence of a data flow between two systems, but the complete description of how and where data is sourced, where it is traveling to, and the detailed mechanics of how it moves between the two endpoints.
Just as a reified Employment relationship captures not just "Person A works at Organization B" but the full context of that connection—role, dates, type, status—a reified Data Integration captures not just "System A sends data to System B" but the full specification of that flow: what data is being sent, in what format, by what transport mechanism, using what technology, and at what frequency. The source system and the target system are the nodes. Everything else is the tuple.
Consider the following 9-tuple reified relationship that fully describes a data flow between a CRM system and an AWS S3 bucket:

From those nine tuple attributes, the system can immediately generate a precise semantic sentence: "The CRM System (Application) sends Signed Final Quote data in JSON format to the Sales Quote Object Repository (AWS S3 Bucket) via an Informatica IICS ETL job, running hourly." That sentence is an exact, human-readable description of a live data integration—derived entirely from the structured attributes of the reified relationship record.
This framing has significant practical implications for how organizations manage their integration estates. A bare 2-tuple record stating only that the CRM System connects to the Sales Quote Object Repository says almost nothing useful. An organization managing hundreds or thousands of integrations using only 2-tuple records has a catalog of connections, not a catalog of knowledge. It cannot answer the questions that matter: what data is flowing? In what format? Via what technology? How often? What happens if the source system is decommissioned or the target bucket is renamed?
Reifying data integrations as rich N-tuple relationship records—capturing source, target, payload, format, transport type, technology, frequency, and any other operationally relevant attributes—transforms an integration inventory from a list of connections into a genuine knowledge base about the organization's data flows. Each reified integration record contributes to the Knowledge Profiles of both the source and target components it connects, making those nodes far more descriptively complete within the graph. And as with all reified relationships, the more tuple attributes the record carries, the richer the semantic sentences it can generate—and the more powerfully it supports analysis, impact assessment, lineage tracing, and governance.
The practical significance of this transformation extends well beyond analytics and governance into one of the most common and most costly activities in enterprise IT: diagramming. Traditionally, enterprise data flow diagrams—schematics showing which systems send data to which other systems—are created manually using tools such as Visio, Lucidchart, or draw.io. A data architect or integration engineer opens the tool, draws a box for each system, and connects the boxes with lines. Those lines typically carry little or no structured information: perhaps an arrow indicating direction, sometimes a short label, rarely anything describing the payload, format, transport mechanism, or frequency of the flow. The diagram reflects whatever the author happened to know at the time of creation. It is not derived from any authoritative data source. It is a hand-drawn interpretation.
The consequences are well understood by anyone who has worked in enterprise IT. Manual diagrams are slow to produce: a reasonably complete diagram of an integration landscape with fifty systems may take days or weeks to draft. They are error-prone: the author may misremember or misidentify a connection, and no validation mechanism exists to catch the error. They go stale almost immediately: every new integration, every decommissioned system, every changed payload represents a manual update that rarely happens in practice. And they are fragmented: different teams in the same organization independently produce diagrams of overlapping integration landscapes using inconsistent notation, inconsistent scope, and inconsistent levels of detail. The result is a collection of diagrams that cannot be trusted, cannot be reconciled, and cannot be queried.
When data integrations are properly reified—when each flow is inventoried as a structured N-tuple record capturing source, target, payload, format, transport type, technology, frequency, and all operationally relevant attributes—the diagram ceases to be a manually maintained artifact and becomes a derivable output. The schematic is no longer drawn; it is generated directly from the data. Any change to the underlying integration inventory is immediately reflected in any diagram produced from it. Different teams working from the same reified data source produce diagrams that are consistent by construction, because they share the same underlying records.
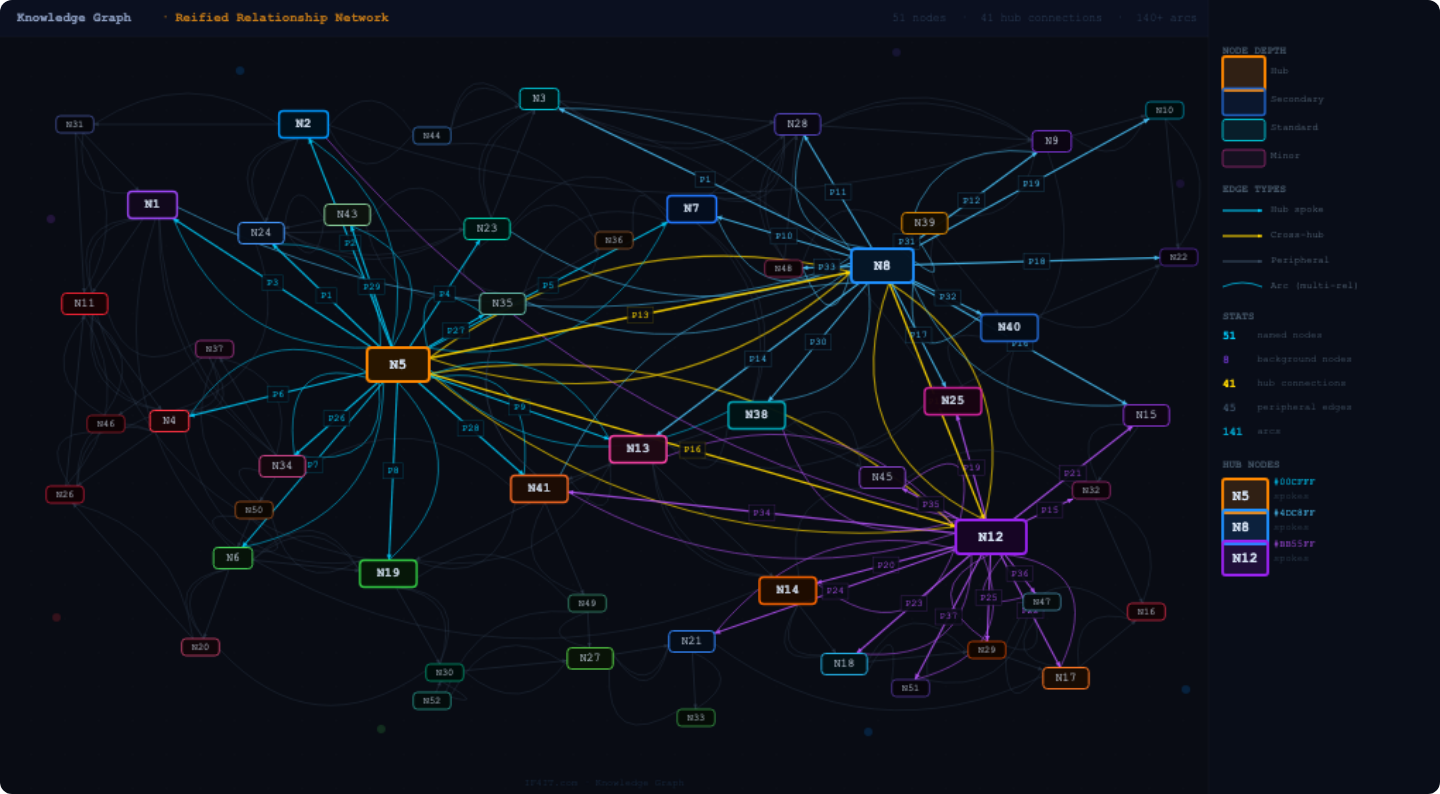
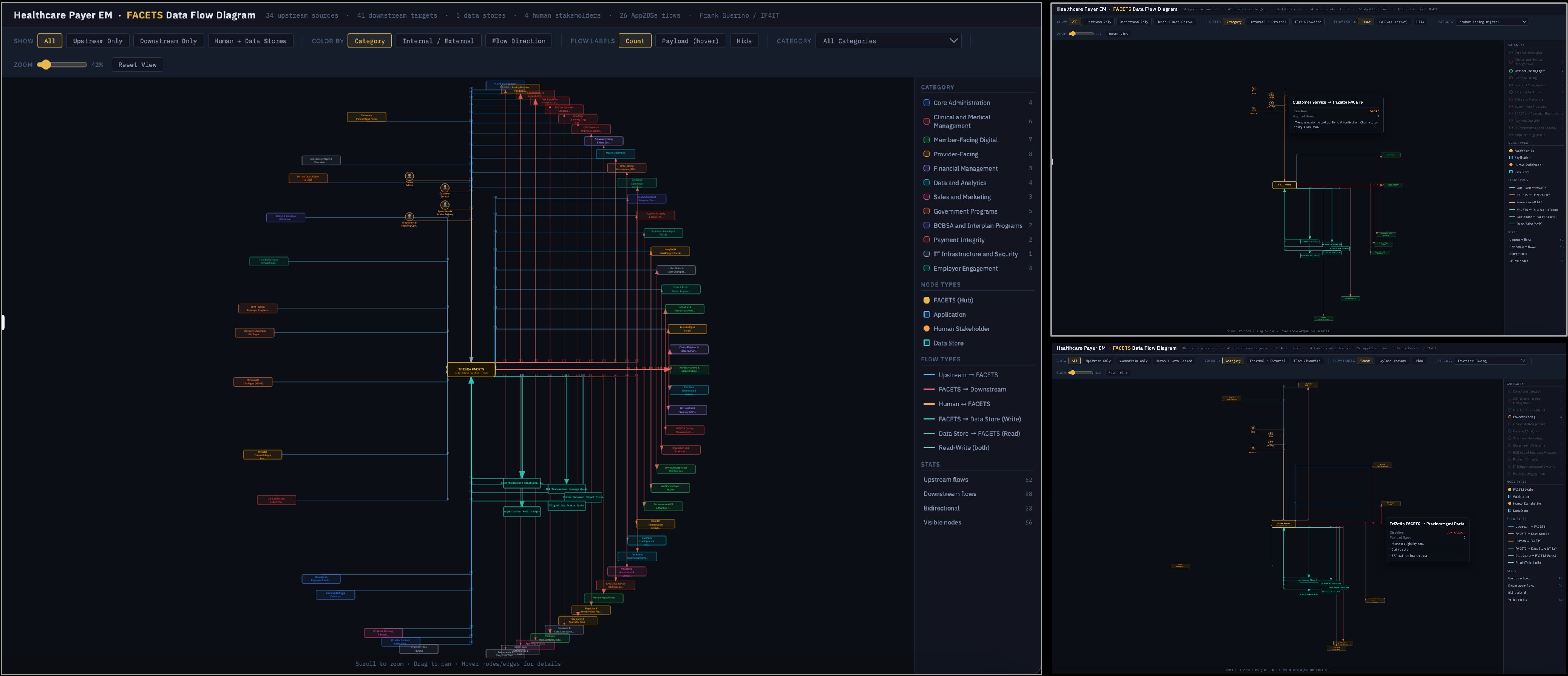
The visualization below is a direct example of this principle in practice. It was produced automatically by Claude AI from a structured inventory of reified data integrations within a Healthcare Payer Enterprise Model. The diagram maps the complete data flow landscape around the TriZetto FACETS system—34 upstream sources, 41 downstream targets, 5 data stores, and 4 human stakeholders, with 26 application-to-application flows—color-coded by category, filterable by flow direction, and interactive at the edge level to expose the full N-tuple attributes of each reified integration relationship. No line was drawn manually. No box was placed by hand. The entire schematic, including its color scheme, its legend, its filter controls, and its edge-level metadata, was derived automatically from the reified relationship records in the integration inventory. This is what becomes possible when data integrations are treated as first-class reified N-tuple relationships rather than as informal, manually diagrammed connections.
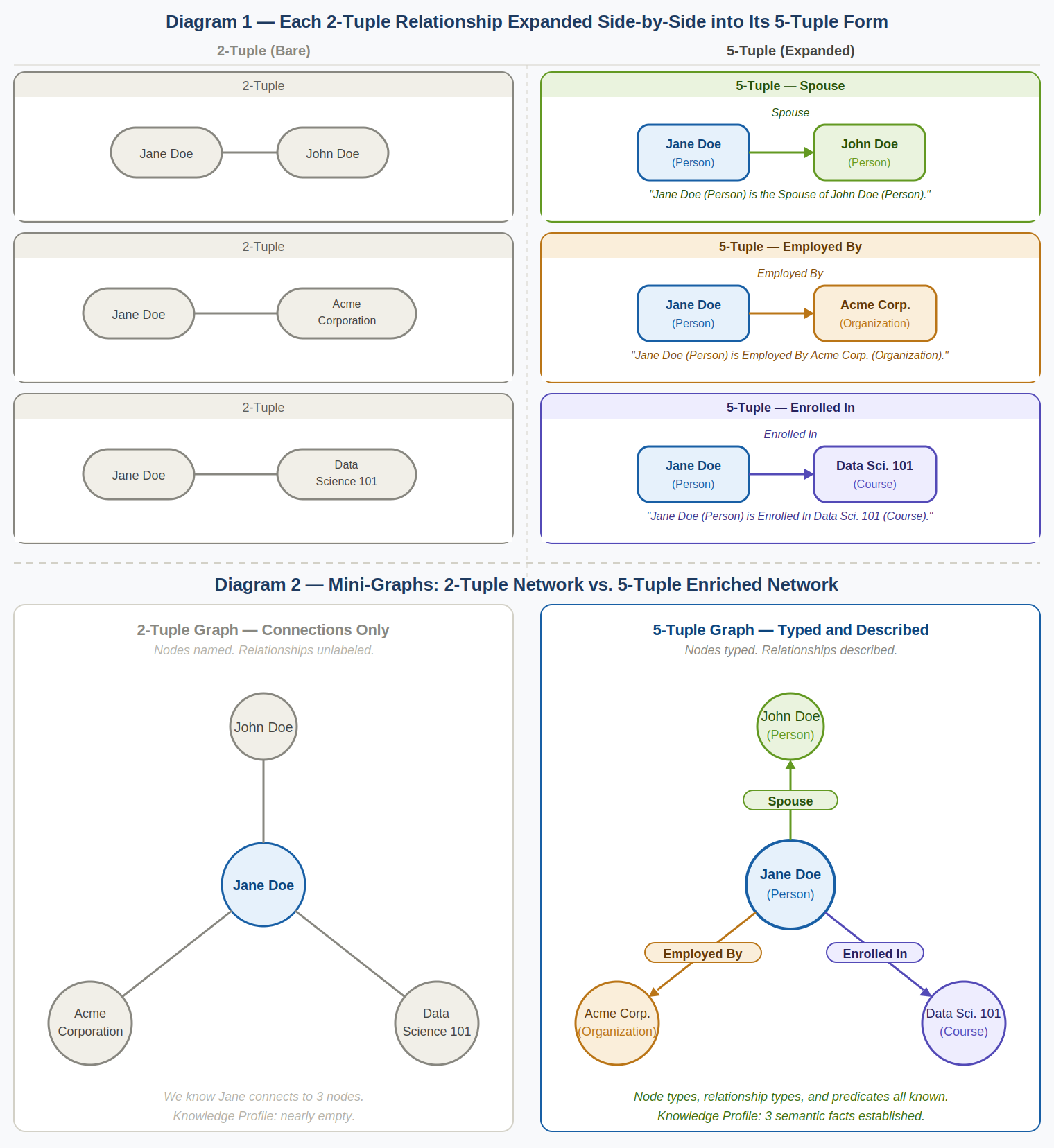
Once a relationship has been reified into a data record, that record has a structure. It contains a specific set of attributes—fields that describe the connection. The term N-tuple provides a precise way to describe the shape of that structure.
In relational theory, a tuple is a single, ordered set of attribute values—essentially a row in a table. The "N" in N-tuple refers to the degree of the tuple: the number of attributes it contains. A 2-tuple has two attributes. A 5-tuple has five. A 10-tuple has ten.
A reified relationship with a low N is a sparse description of the connection. A reified relationship with a higher N carries more context, more history, and more meaning—and contributes more to the Knowledge Profiles of the nodes it connects. Some common N-tuple forms have their own names:
1-tuple (Monuple): A record with a single attribute. Rare in practice.
2-tuple (Pair or Binary Tuple): A record with two attributes. In a reified relationship context, this is the minimal form—a source node and a target node. It answers only whether these two instances are connected, saying nothing about the nature of the connection.
3-tuple (Triple): A record with three attributes. The foundation of RDF data models, where every fact is expressed as a subject-predicate-object triple.
4-tuple (Quad or Quadruple): A record with four attributes. Common in knowledge graph systems where a named graph or context is added to the triple.
5-tuple (Quintuple): A record with five attributes. A natural minimum for a semantically complete reified relationship.
The power of the 5-tuple becomes clear with a concrete example. A 5-tuple structured as: Source Node Type = Person, Source Node = Jane Doe, Descriptive Predicate = Spouse, Target Node Type = Person, Target Node = John Doe immediately generates the sentence: "Jane Doe, who is a Person, is the Spouse of John Doe, who is also a Person." Compare that to a bare 2-tuple of Jane Doe and John Doe, which produces only: "Jane Doe is connected to John Doe." The predicate and the node types transform a meaningless link into a precise, human-readable fact.
Knowledge Profiles: What a Node Knows About Itself
A single reified relationship tells us something about two nodes. A collection of reified relationships tells us a great deal. When the full set of reified relationships connected to a node is assembled and examined together, it forms that node's Knowledge Profile (KP)—the complete picture of everything the graph knows about that node, expressed through the totality of its connections.
A Knowledge Profile is not an attribute of the node itself. It emerges from the graph: from every reified relationship in which the node participates, every predicate that describes those connections, every tuple attribute that adds context to them, and every other node those relationships connect to.
The richness of a Knowledge Profile depends on two factors: the number of reified relationships connected to the node, and the tuple depth of those relationships.
Number of relationships: A Person node with two reified relationships has a sparse Knowledge Profile. The same node with twenty reified relationships—Employment, Address, Education, Spouse, Membership, Publication, Award, and more—has a dramatically richer profile.
Tuple depth: A Person node whose Employment relationship is a 2-tuple contributes almost nothing to the KP beyond the fact of the connection. The same relationship as a 9-tuple—adding job title, department, employment type, compensation band, start date, end date, and status—contributes a detailed, semantically rich description of one dimension of that person's life.
Knowledge Profiles also enable comprehensive natural-language narratives. Given a Person node with six reified relationships averaging 7-tuple depth, the system can generate a multi-sentence portrait assembled from the semantic sentences of each relationship—describing who the person is, what they do, where they have been, and what they know. Knowledge Profiles also reveal gaps: a node with sparse relationships or shallow tuple depths has a thin KP that cannot support deep analysis or reliable reasoning.
At organizational scale, the goal of a well-built knowledge graph can be restated in Knowledge Profile terms: every node that matters should have a Knowledge Profile comprehensive enough to answer the questions the organization needs to ask about it.
The Benefits of Reified Relationships and the Power of Tuples
Reification fundamentally changes what a data system can know, say, and do with the connections it contains.
Relationships describe how nodes are connected. An unlabeled edge between two nodes conveys almost nothing. A reified relationship gives that edge a name, a direction, a type, and a context. It answers not just "are these two nodes connected?" but "how are they connected, and what does that connection mean?"
More tuples mean richer descriptions and richer Knowledge Profiles. A 2-tuple says only that two nodes are connected. A 9-tuple says how, when, in what role, and under what conditions—and contributes nine dimensions of knowledge to each connected node's Knowledge Profile.
Richer tuples enable more powerful semantic sentences. A reified relationship is a structured description of a real-world fact that can be read as a sentence. The richer the tuple, the more precise and informative that sentence becomes. When the full set of a node's reified relationships is traversed, their sentences can be assembled into a complete Knowledge Profile narrative.
They support relationship-level analytics. When connections are reified, they become queryable. How many active employment relationships exist in a given department? How many prescriptions for a specific medication were initiated in a given quarter? None of these questions are answerable when relationships carry no data.
They support temporal modeling. Reification allows changes over time to be tracked explicitly, with timestamps and status attributes on the relationship record itself, without altering the underlying node records.
They make implicit knowledge explicit. The history of a connection—when it started, how it changed, when it ended—is lost unless captured in a reified record. Reification is the mechanism by which implicit connections become explicit, persistent, queryable contributions to a node's Knowledge Profile.
The Relationship Between Reification and N-Tuples
Every reified relationship is a tuple. Its degree—its N—is determined by how many attributes are needed to fully describe the connection it represents. Consider how N evolves for a reified employment relationship:
Minimal (2-tuple): Source Node and Target Node only. Contributes almost nothing to either node's Knowledge Profile.
Basic (4-tuple): Source Node, Target Node, Start Date, End Date. Captures duration but no role or status.
Standard (6-tuple): Adds Job Title and Department. Supports workforce reporting and begins to enrich Knowledge Profiles meaningfully.
Rich (9-tuple): Adds Employment Type, Compensation Band, and Status. Supports detailed analytics, compliance reporting, semantic sentence generation, and deep Knowledge Profile construction.
Each step up in N adds analytical capability, semantic expressiveness, and Knowledge Profile depth. The right N depends on the questions the data system needs to answer and the completeness of Knowledge Profile it needs to maintain.
Why Manual Reification of Relationships Fails at Scale
The concept of reification is straightforward. The implementation of reification at meaningful scale is not. One of the most persistent mistakes in data engineering is the assumption that human analysts and data modelers can manually create and maintain a complete, accurate network of reified relationships—and therefore complete Knowledge Profiles for every node that matters.
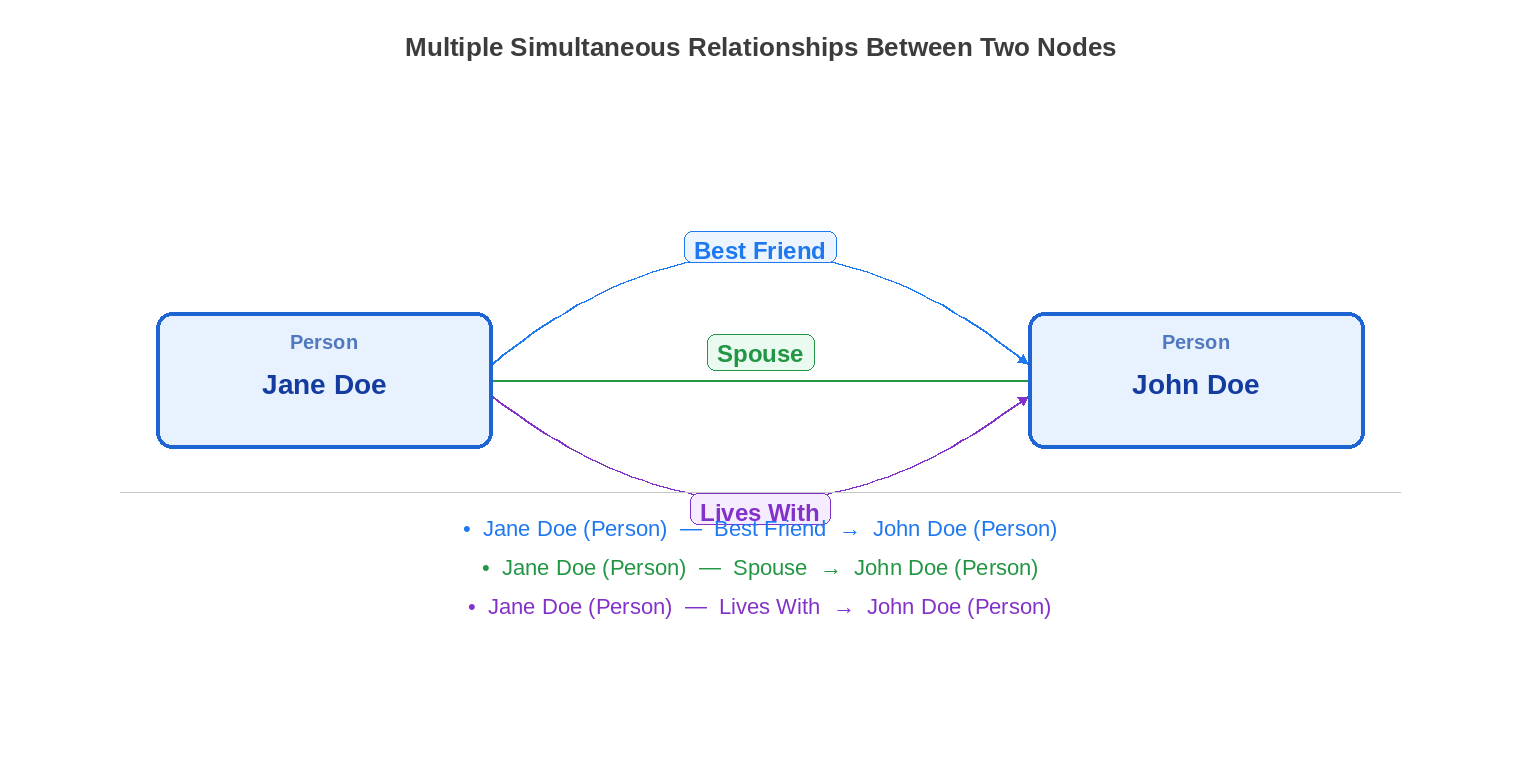
The challenge is compounded by a structural reality of knowledge graphs that manual approaches almost always undercount: any two nodes can have multiple distinct, simultaneous relationships between them. Jane Doe and John Doe are not connected by a single relationship—they may be connected by many. She is his Spouse. She is also his Best Friend. She Lives With him. She may additionally be his Business Partner, his Emergency Contact, and the Beneficiary of his life insurance policy. Each of these is a separate, independently reified relationship record with its own predicate, its own tuple attributes, its own lifecycle, and its own contribution to both nodes’ Knowledge Profiles. None of them can stand in for any other. In a complete and accurate knowledge graph, all of them must be modeled and maintained.
The diagram below illustrates three simultaneous reified relationships between a single pair of Person nodes. One is rendered as a direct connection; the other two are arcs, reflecting the reality that multiple distinct predicates can connect the same two nodes at the same time. This is not an edge case—it is the norm in any richly modeled graph.
The combinatorial explosion of relationships. In a data graph, the number of potential relationships between nodes grows combinatorially with the number of nodes. A graph with ten nodes has at most 90 directed relationships. A graph with one thousand nodes has up to nearly one million. An enterprise data environment with tens of thousands of entity instances has a theoretical relationship space in the billions. A single node in a well-modeled enterprise graph may require dozens of reified relationships to produce a genuinely complete Knowledge Profile.
The underestimation of maintenance burden. Reified relationships are not static. The real-world connections they describe change: statuses evolve, roles change, dates shift. Every change in the underlying world is a potential change to one or more reified relationship records—and therefore a potential change to a node's Knowledge Profile. A single stale or incorrect relationship can propagate errors through every query, analysis, or semantic sentence that traverses it.
The inconsistency problem. When reification is performed manually, consistency is difficult to enforce at scale. Different analysts model the same relationship type with different tuple structures. Some records have rich 9-tuple descriptions; others have sparse 3-tuple descriptions of nominally the same relationship. The result is a graph with internally inconsistent Knowledge Profiles.
The coverage gap. Manual reification leaves gaps. Human teams inevitably miss connections that are recorded in structured or unstructured data but that no analyst has modeled and reified. The result is Knowledge Profiles that are locally dense in areas teams have focused on, and missing critical relationship dimensions everywhere else.
The cumulative effect is a graph that cannot deliver on the promise of comprehensive Knowledge Profiles. Manual reification is not a viable long-term strategy for any data environment of meaningful scale.
Using Data Compilers to Automatically Synthesize Reified Relationships at Scale
The scale problem that defeats manual reification is precisely the kind of problem that automated systems are designed to solve. A data compiler—a configurable, rule-driven system trained to scan data sources and extract structured relationships from them—can produce reified relationships at a volume, speed, consistency, and cost that no human team can match, building Knowledge Profiles that are comprehensive in coverage and consistent in structure.
What a data compiler does. A data compiler reads data across multiple source types—structured databases, semi-structured formats such as JSON, XML, and CSV, and unstructured content such as documents, emails, reports, and web pages—and applies a set of configurable rules to identify, extract, and construct reified relationship records.
Configured rules, not hard-coded logic. The power of a data compiler lies in its configurability. Rather than being hard-coded for a specific domain, it is trained through rules that data architects and domain experts can define, refine, and extend. A rule might specify: "when a document contains a reference to a Person node and an Organization node in the context of an employment verb, extract the person identifier, the organization identifier, the job title if present, and the date references, and construct a 7-tuple Employment reified relationship record."
Coverage across all data types. A large share of meaningful relationship evidence is locked in unstructured content: the contract describing a vendor relationship, the email establishing a project assignment, the clinical note recording a prescription. A data compiler can extract reified relationships from all of these sources, transforming evidence buried in documents into structured graph data that enriches Knowledge Profiles systematically.
Volume, speed, and consistency. A data compiler can produce reified relationship records at a rate orders of magnitude higher than manual methods—thousands or tens of thousands of records per hour. Because the extraction logic is rule-governed, every relationship of a given type is modeled with the same tuple structure, the same attribute mapping, and the same validation logic. The inconsistency problem that plagues manual reification is structurally eliminated.
Continuous maintenance at scale. A data compiler operates continuously or on a scheduled basis, rescanning data sources for new evidence, detecting changes to existing relationships, and updating or retiring reified relationship records as the underlying data evolves. Knowledge Profiles stay current without manual intervention.
Lower cost, higher accuracy. The cost of manual reification grows linearly with volume. The cost of automated compilation grows much more slowly. For large-scale graph construction, automated compilation is not just faster and more consistent than manual methods; it is dramatically less expensive per relationship record produced.
Reification in Different Data Paradigms
Relational databases: Reification is implemented through associative entities or junction tables with additional columns. A many-to-many relationship between Student nodes and Course nodes becomes an Enrollment table with its own attributes, contributing to the Knowledge Profiles of both the student and the course.
RDF and knowledge graphs: In RDF data models, every fact is expressed as a triple: subject, predicate, object. Reification in RDF means creating a new resource that represents the triple itself, allowing additional statements to be made about the fact—such as who asserted it, when, and with what confidence.
Object-oriented and UML modeling: Reification appears as the association class—a class that represents a relationship between two other classes and carries its own attributes. An Employment association class between Person and Organization carries salary, title, and tenure as attributes of the relationship itself.
Property graphs: Graph databases such as Neo4j allow edges to carry properties directly. The concept of a Knowledge Profile emerges naturally from traversing all edges connected to a given node and aggregating their properties.
A Practical Note on Design
Not every relationship needs to be reified. Simple, stable, context-free connections—a product belonging to a category, a city being located in a country—rarely benefit from reification in general-purpose data models. The signal that reification is warranted is the presence of attributes that belong to the connection rather than to either of the connected nodes.
That said, there are important exceptions. Whether a relationship warrants reification—and to what tuple depth—depends entirely on the level of detail required for the specific use case at hand. A relationship that looks simple in one context can be rich with meaning in another.
Consider the example of a city being located in a country. For most general purposes, a bare 2-tuple connection between a City node and a Country node is sufficient: Paris is in France. But a geopolitical analyst, a historian, or a legal jurisdiction system may need to reify that relationship into a much richer record. When did Paris become part of France? Under what treaty or political arrangement? What is the administrative classification of that relationship? Has it changed over time, and if so, when and why? A 7-tuple or 8-tuple reified relationship between Paris and France—capturing the effective date, the legal basis, the administrative tier, the historical continuity flag, and the source of record—is entirely appropriate for those use cases, even though it would be unnecessary overhead for a simple address validation system.
The same logic applies across domains. A product belonging to a category is a simple 2-tuple for a retail catalog. It becomes a candidate for reification in a regulatory compliance system that needs to track when the product was added to the category, under what classification standard, by which authority, and with what effective and expiry dates. The relationship has not changed—only the analytical requirements have.
The practical design question is therefore not "should this relationship be reified?" in the abstract, but "what does this use case need to know about this connection?" That question determines both whether reification is warranted and what N should be. A connection that appears context-free at one level of analysis may reveal rich, tuple-worthy attributes the moment the use case demands deeper inspection. Designing for that possibility—even if the initial implementation starts with a low N—is a mark of a mature data architecture.
Getting the N right matters. Too low, and the reified relationship produces thin Knowledge Profile contributions that cannot support the analysis it was designed for. Too high, and the record becomes a maintenance burden with fields that are rarely populated accurately. The goal is a tuple whose degree reflects the genuine informational requirements of the connection for the use case at hand—with the understanding that those requirements may grow, and the data model should be designed to accommodate that growth.
Closing Thought
Data systems that treat relationships as invisible connectors are data systems that lose information. The history of how nodes connect—when, why, under what conditions, and in what roles—is often as valuable as the data about the nodes themselves. Reification is the mechanism that preserves that information. N-tuple notation is the vocabulary for describing how richly a reified relationship captures it. And Knowledge Profiles are the measure of how completely a graph represents everything it knows about each node it contains.
A Knowledge Profile is ultimately a statement of understanding: here is what this system knows about this entity, expressed through the full network of its reified relationships. A thin Knowledge Profile says the system knows little. A rich Knowledge Profile—many relationships, deep tuples, diverse predicates—says the system knows a great deal, and can generate precise semantic descriptions, support sophisticated reasoning, and answer complex questions about the entity it represents.
Building rich, complete Knowledge Profiles at meaningful scale requires the right conceptual framework and the right tooling. The conceptual framework is reification and N-tuple analysis. The tooling is automated data compilation—configurable, rule-driven, operating continuously across structured, semi-structured, and unstructured data. Together, they make comprehensive Knowledge Profiles achievable rather than aspirational, and transform a data graph from a collection of connections into a living, queryable model of the world.
Published by IF4IT.com — The International Foundation for Information Technology